728x90
반응형
SMALL
Matplotlib은 Matlab과 비슷한 명령어 스타일로 동작하는 함수의 모음으로 파이썬 기반 시각화 라이브러리입니다. pandas와 호환성이 높아 연동이 용이하지만, 한글 지원이 완벽하지 않다는 단점이 있습니다.
Matplotlib로 간단한 그래프 그리기
python
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.show()

python
plt.plot([1,2,3,4], [1,4,10,15])
plt.show()
python
import numpy as np
data = np.arange(1, 100)
plt.plot(data)
plt.show()
다수 그래프 그리기
python
data1 = np.arange(1, 50)
plt.subplot(2, 1, 1)
plt.plot(data1)
data2 = np.arange(50, 100)
plt.subplot(2, 1, 2)
plt.plot(data2)
plt.show()

python
data1 = np.arange(0, 100)
plt.subplot(131)
plt.plot(data1)
data2 = np.arange(0, 100)
plt.subplot(132)
plt.plot(data2)
data3 = np.arange(0, 100)
plt.subplot(133)
plt.plot(data3)
plt.show()
Matplotlib 스타일 옵션
Matplotlib를 사용한 시각화를 더욱 예쁘고 효과적으로 꾸미기 위해서는 스타일 옵션을 사용할 수 있습니다. 이를 위해서는 먼저 Colab에 나눔체를 설치한 후 아래 코드를 실행해야 합니다.
python
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
python
import matplotlib.pyplot as plt
plt.rc('font', family = 'NanumBarunGothic') # 나눔바른고딕 폰트 사용
plt.figure(figsize=(6, 8)) # 그래프 크기 지정
plt.plot([1,2,3], [1,2,3])
plt.plot([1,2,3], [2,4,6])
plt.title('타이틀', fontsize=30)
plt.xlabel('X축', fontsize=20)
plt.ylabel('Y축', fontsize=20)
.show()

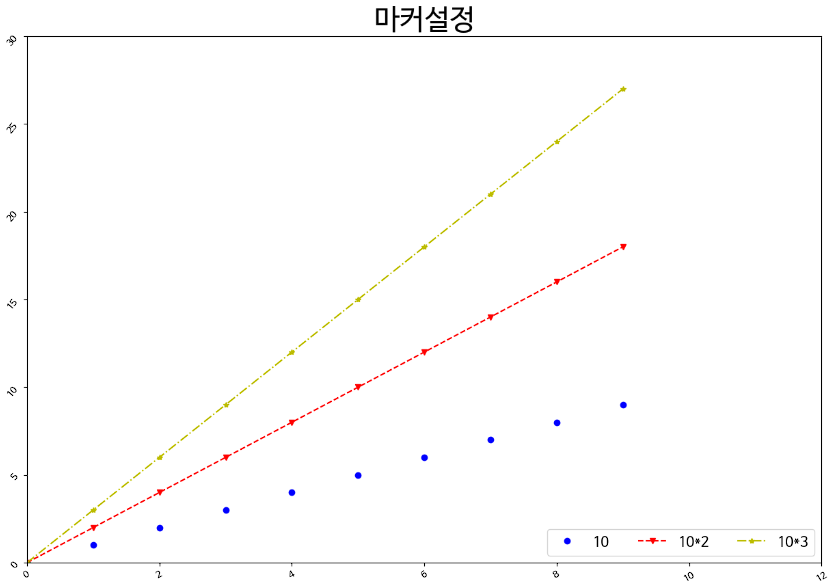
python
plt.figure(figsize=(15, 10))
plt.title('마커설정', fontsize=30)
plt.plot(np.arange(10), np.arange(10), color='b', marker='o', linestyle='')
plt.plot(np.arange(10), np.arange(10)*2, color='r', marker='v', linestyle='--')
plt.plot(np.arange(10), np.arange(10)*3, color='y', marker='*', linestyle='-.')
plt.legend(['10', '10*2', '10*3'], fontsize=15, loc='lower right', ncol=3) #
plt.xlim(0, 12)
plt.ylim(0, 30)
plt.xticks(rotation=30)
plt.yticks(rotation=50)
plt.show()
Matplotlib을 이용한 바 차트 그리기
Matplotlib를 이용하여 바 차트를 그는 방법은 다음과 같습니다.
python
x = ['파이썬', '데이터분석', '머신러닝', '딥러닝', '컴퓨터비전', '자연어처리']
y = [ 95, 80, 65, 30, , 10]
plt.figure(figsize=(8, 5))
plt.bar(x, y, align='center',alpha=0.7, color='#e35f62')
plt.title('AI 성적표', fontsize=25)
plt.ylabel('점수')
plt.show()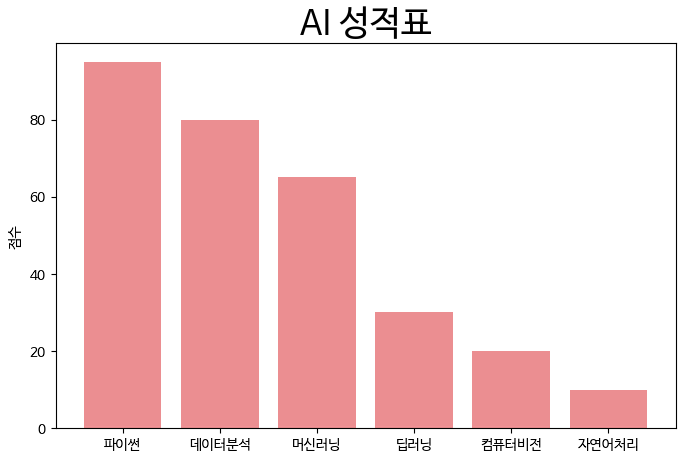
728x90
반응형
LIST
'데이터분석' 카테고리의 다른 글
| 워드클라우드 라이브러리 (0) | 2023.06.11 |
|---|---|
| 자연어 처리를 위한 기본적인 이해와 활용 (Feat. KoNLPy) (0) | 2023.06.08 |
| Pandas - rank, datetime, apply, map (0) | 2023.06.08 |
| Pandas 데이터프레임 합치기 (0) | 2023.06.08 |
| Pandas 중복값 제거 (0) | 2023.06.08 |